本文为非官方中文翻译,内容以 OpenAI 官方英文文档为准。
官方来源:https://developers.openai.com/cookbook/examples/codex/build_iterative_repair_loops_with_codex
使用 Codex 构建迭代式修复循环
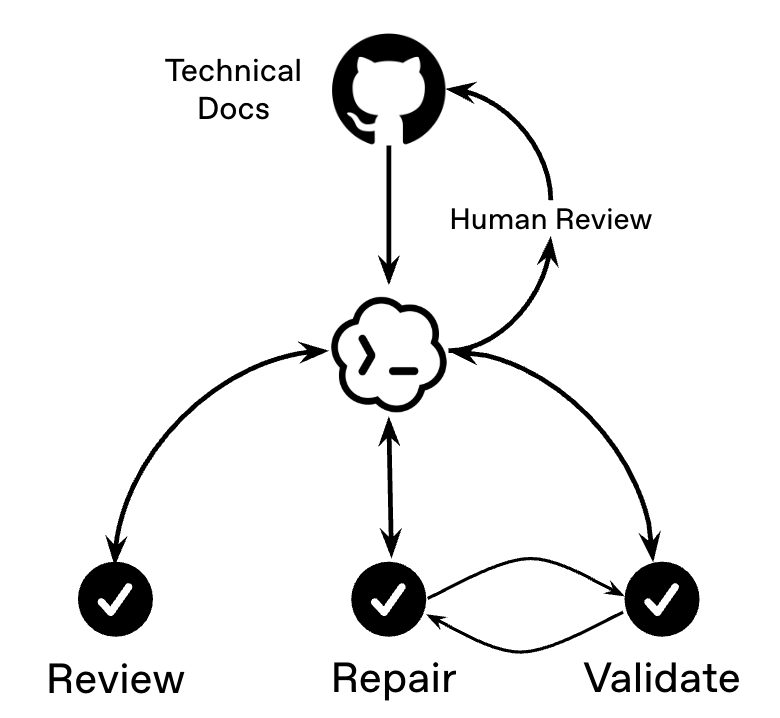
本 cookbook 介绍闭环 agent 工作流:agent 先产出结果,再进行验证,并利用反馈改进下一轮结果。
我们将探索一个文档可靠性工作流,用于检测、修复并验证过时或失效的 API 和 SDK 示例。示例中使用了来自本 Cookbook 仓库、经过刻意陈旧化处理的 notebook。
我们将使用 Codex 构建这个 agent 循环。Codex 会审查当前状态,应用有针对性的修改,运行验证,并在反馈显示仍有问题时继续重复。
notebook 任务只是一个示例。只要 agent 的输出能够通过可信反馈进行衡量,这种模式都适用。
该工作流包含三个阶段:
- Review: 检查当前产物并返回结构化发现,不编辑文件。
- Repair: 基于这些发现和最新的验证反馈,对复制出的产物进行有针对性的编辑。
- Validate: 运行相关检查,并报告仍需处理的问题。
验证会闭合这个循环。修复后的 notebook 必须通过关键检查,任何剩余问题都会成为下一轮修复的输入。
设置
此 notebook 在无头模式下使用 Codex CLI,因此修复步骤可以从 Python 单元运行,而不是通过聊天 UI。如果你已经安装了 CLI,可以跳过第一个代码单元。
在运行实时修复循环之前,请在环境中设置 OPENAI_API_KEY。
该 notebook 默认使用一个较快的修复模型,以便完整示例能在合理时间内完成。若要尝试不同模型,请在开始前设置 REPAIR_MODEL。安装单元会固定一个已知的 Codex CLI 版本以保证可复现性;当你需要较新的 CLI 行为时,请有意地更新该版本。
!npm install -g @openai/codex@0.130.0
from pathlib import Path
from typing import Any
CANDIDATE_EXAMPLE_DIRS = [Path("."), Path("examples/codex")]
EXAMPLE_DIR = next((base for base in CANDIDATE_EXAMPLE_DIRS if (base / "data" / "docs").exists()), None)
if EXAMPLE_DIR is None:
raise RuntimeError(
"This notebook needs its companion sample notebooks. "
"Download the data folder that ships with this example and place it next to "
"this notebook as ./data/docs, or run from a checkout where examples/codex/data/docs exists."
)
DATA_DIR = EXAMPLE_DIR / "data" / "docs"
DEFAULT_RUNS_DIR = Path(tempfile.gettempdir()) / "codex_iterative_repair_loop_outputs"
RUNS_DIR = Path(os.getenv("CODEX_REPAIR_RUNS_DIR", str(DEFAULT_RUNS_DIR))).expanduser()
RUNS_DIR.mkdir(parents=True, exist_ok=True)
MODEL = os.getenv("REPAIR_MODEL", "gpt-5.4-mini")
COOKBOOK_CHAT_MODEL = os.getenv("COOKBOOK_CHAT_MODEL", "gpt-5.5")
REPAIR_REASONING_EFFORT = os.getenv("REPAIR_REASONING_EFFORT", "low")
if not os.environ.get("OPENAI_API_KEY"):
raise ValueError("Set the OPENAI_API_KEY environment variable before running the live Codex repair loop.")
CODEX_CLI = shutil.which("codex")
if CODEX_CLI is None:
raise RuntimeError("Run the install cell before continuing; Codex CLI is not on PATH.")
加载示例产物
下面的单元会加载三个配套 notebook,并汇总驱动修复循环的元数据。
这些示例刻意保持较小规模。它们运行很快,但仍然能够覆盖这套架构:review 会发现实质性问题,repair 会进行有针对性的编辑,而 validation 会产出下一轮所需的反馈。
如果你只下载了这个 notebook,也请一并下载配套的 data/docs/ 文件夹,并在运行下面单元前将其放到 notebook 旁边。代码要求这些示例 notebook 在本地可用。
在此示例中,validation 会端到端执行每个修复后的 notebook。在其他领域中,validation 也可能是单元测试、策略检查、schema 验证器、仿真,或人工审批步骤。关键在于:失败会变成结构化反馈,而不是走入死胡同。
NOTEBOOKS = [
DATA_DIR / "qdrant_embeddings_search_pre_repair.ipynb",
DATA_DIR / "getting_started_evals_pre_repair.ipynb",
DATA_DIR / "knowledge_retrieval_pre_repair.ipynb",
]
def read_notebook(path: Path) -> dict[str, Any]:
return json.loads(path.read_text(encoding="utf-8"))
def case_metadata(path: Path) -> dict[str, Any]:
return read_notebook(path).get("metadata", {}).get("codex_case_study", {})
cases = []
for notebook_path in NOTEBOOKS:
notebook = read_notebook(notebook_path)
metadata = notebook.get("metadata", {}).get("codex_case_study", {})
repair_story = metadata.get("repair_story", {})
cases.append(
{
"notebook": notebook_path.name,
"cells": len(notebook["cells"]),
"code_cells": sum(cell["cell_type"] == "code" for cell in notebook["cells"]),
"source": metadata.get("source_path"),
"target_iteration": repair_story.get("target_iteration"),
"repair_depth": repair_story.get("repair_depth", ""),
}
)
cases
[{'notebook': 'qdrant_embeddings_search_pre_repair.ipynb',
'cells': 5,
'code_cells': 4,
'source': 'examples/vector_databases/qdrant/Using_Qdrant_for_embeddings_search.ipynb',
'target_iteration': 1,
'repair_depth': 'One-pass cleanup: modernize the local Qdrant query path and clarify the sampled fixture framing.'},
{'notebook': 'getting_started_evals_pre_repair.ipynb',
'cells': 5,
'code_cells': 4,
'source': 'examples/evaluation/Getting_Started_with_OpenAI_Evals.ipynb',
'target_iteration': 2,
'repair_depth': 'Two-pass cleanup: first modernize the obvious stale Evals flow, then use validation feedback to remove result-log brittleness.'},
{'notebook': 'knowledge_retrieval_pre_repair.ipynb',
'cells': 5,
'code_cells': 4,
'source': 'examples/How_to_call_functions_for_knowledge_retrieval.ipynb',
'target_iteration': 3,
'repair_depth': 'Three-pass cleanup: modernize model/API shape, then tighten runnable local setup, then restore the full retrieval teaching flow.'}]
定义业务规则和问题分类法
在让 Codex review 或 repair 某个产物之前,先给它一个小而共享的契约。这样能让循环聚焦于真正重要的问题,而不是让模型从零开始推断所有产品和风格规则。
下面的规则定义了这些示例 notebook 中“好”的含义:当前 API 模式、清晰的设置、可在本地运行的示例,以及保留原始教学目标。在其他工作流中,这个契约则会描述该领域的事实来源。
business_rules = {
"preferred_chat_model": COOKBOOK_CHAT_MODEL,
"preferred_embedding_model": "text-embedding-3-large",
"modernize": [
"client.chat.completions.create -> client.responses.create",
"legacy function-calling schemas -> current tools schema",
"qdrant.search -> qdrant.query_points",
"oaieval CLI examples -> current Evals API workflow",
],
"reader_experience": [
"Make fresh-environment setup explicit.",
"Keep the included examples runnable with local data and the standard library.",
"Keep sample repairs self-contained unless the notebook explicitly teaches external setup.",
"Remove manual result-file placeholders.",
"State runtime prerequisites and side effects before readers run cells.",
"Preserve the original teaching goal while modernizing the implementation.",
],
}
business_rules
定义结构化输出
每个阶段都会返回结构化数据,以便下一阶段有具体内容可用。
Review 返回发现。Repair 返回变更摘要以及更新后产物的路径。Validation 返回下一轮所需的剩余差距。有了这种结构化交接,这个循环就更容易调试、重跑,并适配到其他类型的产物。
def object_schema(properties: dict[str, Any], required: list[str] | None = None) -> dict[str, Any]:
return {
"type": "object",
"properties": properties,
"required": required or list(properties),
"additionalProperties": False,
}
def string_array() -> dict[str, Any]:
return {"type": "array", "items": {"type": "string"}}
finding_schema = object_schema(
{
"artifact": {"type": "string"},
"issue_type": {"type": "string"},
"severity": {"type": "string"},
"description": {"type": "string"},
"suggested_fix_direction": {"type": "string"},
}
)
review_schema = object_schema(
{"findings": {"type": "array", "items": finding_schema}}
)
fix_schema = object_schema(
{
"artifact": {"type": "string"},
"iteration": {"type": "integer"},
"changes_made": string_array(),
"unresolved_items": string_array(),
"updated_artifact_path": {"type": "string"},
}
)
validation_case_schema = object_schema(
{
"name": {"type": "string"},
"passed": {"type": "boolean"},
"severity": {"type": "string"},
"evidence": {"type": "string"},
"feedback": {"type": "string"},
}
)
validation_schema = object_schema(
{
"overall_passed": {"type": "boolean"},
"cases": {"type": "array", "items": validation_case_schema},
"remaining_delta": string_array(),
}
)
审查阶段
审查阶段读取工件并返回结构化的问题发现。它不会运行验证,也不会编辑文件。这种分离让第一步保持专注:在更改任何内容之前识别可能的问题。
我们将审查提示词连同一个 JSON schema 一起发送给 codex exec。这个 schema 让结果保持机器可读,因此后续单元可以直接将 findings 传入修复提示词,而不必从上一个回答中抓取散文式文本。
def notebook_text(path: Path, max_chars: int = 7000) -> str:
chunks = []
for index, cell in enumerate(read_notebook(path)["cells"]):
source = "".join(cell.get("source", []))
chunks.append(f"cell {index} ({cell['cell_type']})\n{source}")
text = "\n\n".join(chunks)
if len(text) <= max_chars:
return text
return text[:max_chars] + "\n\n[truncated for prompt size]"
def run_command(command: str, *, stdin: str | None = None, cwd: Path | None = None, timeout: int | None = None):
cwd = Path.cwd() if cwd is None else cwd
return subprocess.run(
shlex.split(command),
input=stdin,
cwd=cwd,
capture_output=True,
text=True,
timeout=timeout,
check=False,
)
def run_codex_json(prompt: str, schema: dict[str, Any], run_dir: Path) -> dict[str, Any]:
run_dir.mkdir(parents=True, exist_ok=True)
prompt_file = run_dir / "prompt.txt"
schema_file = run_dir / "schema.json"
answer_file = run_dir / "answer.json"
prompt_file.write_text(prompt, encoding="utf-8")
schema_file.write_text(json.dumps(schema, indent=2), encoding="utf-8")
command = f"""
{CODEX_CLI} exec
--model {MODEL}
--sandbox workspace-write
--ask-for-approval never
--config model_reasoning_effort={REPAIR_REASONING_EFFORT}
--output-schema {schema_file}
--output-last-message {answer_file}
-
"""
result = run_command(command, stdin=prompt)
(run_dir / "stdout.txt").write_text(result.stdout, encoding="utf-8")
(run_dir / "stderr.txt").write_text(result.stderr, encoding="utf-8")
if result.returncode != 0:
raise RuntimeError(f"Codex exited with {result.returncode}. See {run_dir / 'stderr.txt'}.")
return json.loads(answer_file.read_text(encoding="utf-8"))
def review_notebook(path: Path, run_dir: Path) -> list[dict[str, Any]]:
prompt = "\n".join(
[
"You are reviewing a public OpenAI Cookbook notebook before publication.",
f"Artifact: {path.name}",
"Find issues that would make the notebook stale, hard to run, or confusing for a developer reader.",
"Do not execute the notebook or edit files.",
"Use concise issue_type labels such as stale_model, deprecated_api, setup_gap, runtime_risk, or clarity_issue.",
f"Business rules: {json.dumps(business_rules)}",
"Base findings only on the notebook content below.",
"Keep the findings focused; three strong findings are better than a long list.",
"",
notebook_text(path),
]
)
return run_codex_json(prompt, review_schema, run_dir)["findings"]
def run_initial_review(path: Path) -> tuple[str, list[dict[str, Any]]]:
return path.name, review_notebook(path, RUNS_DIR / "initial_review" / path.stem)
with concurrent.futures.ThreadPoolExecutor(max_workers=min(3, len(NOTEBOOKS))) as executor:
initial_reviews = dict(executor.map(run_initial_review, NOTEBOOKS))
initial_reviews
修复阶段
修复阶段获取当前工件、审查 findings、业务规则,以及前一轮中的任何验证反馈。随着循环不断学习,提示词会变得更具体。
Codex 会编辑迭代目录中的一个副本,并返回对变更内容的简短总结。这个循环不会假设编辑已经成功;是否成功由下一步的验证来决定。
def repair_prompt(path: Path, updated_path: Path, findings: list[dict[str, Any]], remaining_delta: list[str], iteration: int) -> str:
repair_story = case_metadata(path).get("repair_story", {})
return "\n".join(
[
"You are repairing a copy of a public OpenAI Cookbook notebook.",
f"Source notebook: {path}",
f"Editable copy: {updated_path}",
f"Iteration: {iteration}",
"Make the smallest useful edits that address the review findings and validation delta.",
"Preserve the notebook's teaching flow and original purpose.",
"Keep sample repairs self-contained unless the notebook explicitly teaches external setup.",
"For staged examples, focus on the most important remaining issue for this pass instead of rewriting everything at once.",
"Edit only the editable copy. Do not claim the notebook passes validation.",
f"Repair depth: {json.dumps(repair_story, indent=2)}",
f"Business rules: {json.dumps(business_rules, indent=2)}",
f"Review findings: {json.dumps(findings, indent=2)}",
f"Remaining validation delta: {json.dumps(remaining_delta, indent=2)}",
]
)
def repair_notebook(path: Path, iteration: int, findings: list[dict[str, Any]], remaining_delta: list[str], case_dir: Path) -> dict[str, Any]:
updated_path = case_dir / "updated.ipynb"
updated_path.parent.mkdir(parents=True, exist_ok=True)
shutil.copy2(path, updated_path)
prompt = repair_prompt(path, updated_path, findings, remaining_delta, iteration)
return run_codex_json(prompt, fix_schema, case_dir / "repair")
验证阶段
验证的工作方式类似一个小型 eval。我们定义想要的行为,运行相关检查,并让一个 judge 根据该评分标准对结果打分。
对于文档示例,首先进行执行。许多 notebook 问题只会在运行时出现:缺失的导入、过时的文件路径、依赖旧 API 响应的单元,或者对作者来说很清楚但对新读者并不清楚的设置说明。
如果验证失败,这个失败就会成为下一轮修复的证据。这让下一轮修复基于已观察到的行为,而不仅仅是 diff 看起来是否正确。
VALIDATION_CASES = [
{
"name": "api_modernization",
"question": "Does the notebook avoid stale OpenAI API patterns, legacy function-calling syntax, and outdated model names?",
},
{
"name": "setup_reproducibility",
"question": "Could a reader run the notebook from a fresh environment without hidden manual steps?",
},
{
"name": "artifact_integrity",
"question": "Did the update preserve the notebook's teaching flow and avoid deleting substantive cells?",
},
]
def short_output(value: Any, limit: int = 1200) -> str:
if value is None:
return ""
if isinstance(value, bytes):
value = value.decode("utf-8", errors="replace")
return str(value)[-limit:]
def execute_notebook(path: Path) -> dict[str, Any]:
code_cells = sum(cell["cell_type"] == "code" for cell in read_notebook(path)["cells"])
command = f"jupyter nbconvert --to notebook --execute --inplace {path.name}"
try:
result = run_command(
command,
cwd=path.parent,
timeout=int(os.getenv("SAMPLE_NOTEBOOK_TIMEOUT_SECONDS", "300")),
)
except FileNotFoundError:
return {
"status": "failed",
"executed_code_cells": 0,
"error": "Jupyter or nbconvert is not installed or is not available on PATH.",
"summary": "Install Jupyter with nbconvert before running the validation loop.",
}
except subprocess.TimeoutExpired as exc:
return {
"status": "failed",
"executed_code_cells": 0,
"error": f"Notebook execution timed out after {exc.timeout} seconds.",
"summary": short_output(exc.stderr or exc.stdout),
}
output = result.stderr or result.stdout
return {
"status": "passed" if result.returncode == 0 else "failed",
"executed_code_cells": code_cells if result.returncode == 0 else 0,
"error": "" if result.returncode == 0 else f"Notebook execution exited with code {result.returncode}.",
"summary": short_output(output),
}
def validation_prompt(updated_path: Path, before_path: Path, execution: dict[str, Any], iteration: int) -> str:
repair_story = case_metadata(before_path).get("repair_story", {})
return "\n".join(
[
"You are judging a repaired OpenAI Cookbook notebook.",
f"Iteration: {iteration}",
"Score each validation case independently and give concise feedback for the next repair pass.",
"Set overall_passed to false when execution failed or any case has a material issue.",
"When execution failed, include the failure in remaining_delta so the next repair pass can address it.",
"Use the business rules as the source of truth for current model names and API targets.",
"Do not mark the preferred embedding model or preferred chat model as stale.",
"For local examples, do not require extra services or package installs when the notebook says it is intentionally self-contained.",
f"Repair depth: {json.dumps(repair_story, indent=2)}",
f"Business rules: {json.dumps(business_rules, indent=2)}",
f"Validation cases: {json.dumps(VALIDATION_CASES, indent=2)}",
f"Execution evidence: {json.dumps(execution, indent=2)}",
f"Original cell count: {len(read_notebook(before_path)['cells'])}",
f"Updated cell count: {len(read_notebook(updated_path)['cells'])}",
"",
notebook_text(updated_path),
]
)
def staged_delta(before_path: Path, iteration: int) -> list[str]:
repair_story = case_metadata(before_path).get("repair_story", {})
target = int(repair_story.get("target_iteration") or 1)
if iteration >= target:
return []
depth = repair_story.get("repair_depth", "This case is intentionally staged across multiple repair passes.")
return [f"Continue to iteration {iteration + 1}: {depth}"]
def evaluate_notebook(updated_path: Path, before_path: Path, run_dir: Path, iteration: int) -> dict[str, Any]:
execution = execute_notebook(updated_path)
judged = run_codex_json(validation_prompt(updated_path, before_path, execution, iteration), validation_schema, run_dir)
failed_cases = [case for case in judged["cases"] if not case["passed"]]
execution_delta = []
if execution["status"] != "passed":
execution_delta.append(f"Execution failed: {execution.get('error') or execution.get('summary')}")
stage_delta = staged_delta(before_path, iteration)
return {
"passed": judged["overall_passed"] and execution["status"] == "passed" and not stage_delta,
"execution_status": execution["status"],
"executed_code_cells": execution["executed_code_cells"],
"execution_summary": execution["summary"],
"findings": failed_cases,
"remaining_delta": execution_delta + stage_delta + judged["remaining_delta"],
}
保存每次迭代的输出
每次迭代都会写入一个 record.json 文件,并且在这个示例中,还会在 CODEX_REPAIR_RUNS_DIR/iteration_N/<sample_name>/ 下保存一个修复后的 notebook。如果你没有设置 CODEX_REPAIR_RUNS_DIR,notebook 会写入系统临时目录,这样普通的 repo checkout 就能保持整洁。
这些文件就是审计轨迹。你可以看到审查发现了什么、Codex 改了什么、执行是否通过,以及哪些反馈被带入了下一次迭代。
record.json 文件是一轮循环尝试的回执。它把各个阶段之间的交接保存在同一个地方:
{
"review": [{"issue_type": "deprecated_api", "severity": "high"}],
"repair": {
"changes_made": ["Updated the notebook to use the current API pattern."],
"updated_artifact_path": "/tmp/codex_iterative_repair_loop_outputs/iteration_1/sample/updated.ipynb"
},
"validation": {
"passed": false,
"remaining_delta": ["One setup instruction is still unclear."]
}
}
这个紧凑的记录让维护者无需从 notebook diff 和终端日志中重建整个运行过程,就能审查这轮循环。
def save_json(payload: Any, path: Path) -> None:
path.parent.mkdir(parents=True, exist_ok=True)
path.write_text(json.dumps(payload, indent=2) + "\n", encoding="utf-8")
def iteration_dir(number: int) -> Path:
path = RUNS_DIR / f"iteration_{number}"
path.mkdir(parents=True, exist_ok=True)
return path
运行第 1 次迭代
每个 notebook 案例彼此独立,因此我们并发处理这些案例。这样既能让演示保持快速,又能为每个样本保留相同的审查、修复和验证流程。
第 1 次迭代会复用前面审查单元中的初始审查结果。完成这一轮后,检查返回的布尔值:通过的案例可以停止,失败的案例则会把它们的验证反馈带入下一轮。
current_notebooks = {path.name: path for path in NOTEBOOKS}
history: dict[int, dict[str, Any]] = {}
def review_findings_for(original: Path, current_path: Path, case_dir: Path, previous_results: dict[str, Any] | None) -> list[dict[str, Any]]:
if previous_results is None:
return initial_reviews[original.name]
return review_notebook(current_path, case_dir / "review")
def run_case(number: int, original: Path, run_dir: Path, previous_results: dict[str, Any] | None) -> tuple[str, dict[str, Any], Path]:
name = original.name
case_dir = run_dir / original.stem
current_path = current_notebooks[name]
findings = review_findings_for(original, current_path, case_dir, previous_results)
delta = [] if previous_results is None else previous_results[name]["validation"]["remaining_delta"]
repair = repair_notebook(current_path, number, findings, delta, case_dir)
updated_path = Path(repair["updated_artifact_path"])
validation = evaluate_notebook(updated_path, current_path, case_dir / "evaluation", number)
record = {"review": findings, "repair": repair, "validation": validation}
save_json(record, case_dir / "record.json")
return name, record, updated_path
def run_iteration(number: int, previous_results: dict[str, Any] | None = None) -> dict[str, Any]:
results = {}
updates = {}
run_dir = iteration_dir(number)
with concurrent.futures.ThreadPoolExecutor(max_workers=min(3, len(NOTEBOOKS))) as executor:
futures = [executor.submit(run_case, number, original, run_dir, previous_results) for original in NOTEBOOKS]
for future in concurrent.futures.as_completed(futures):
name, record, updated_path = future.result()
results[name] = record
updates[name] = updated_path
current_notebooks.update(updates)
history[number] = results
return results
iteration_1 = run_iteration(1)
{name: result["validation"]["passed"] for name, result in iteration_1.items()}
{'qdrant_embeddings_search_pre_repair.ipynb': True,
'getting_started_evals_pre_repair.ipynb': False,
'knowledge_retrieval_pre_repair.ipynb': False}
运行第 2 次迭代
到了第 2 次迭代,这个循环开始显现价值。Codex 不再只是依据原始审查结果工作;它还能看到验证期间发生了什么。
这改变了任务本身。我们不再要求一次宽泛的重写,而是基于上一轮运行中的证据来请求下一步有用的修复:哪些内容执行了、哪些通过了、以及哪些地方仍需关注。
对于这里包含的分阶段 fixture,这一轮的设计目标是解决中等深度的 Evals 案例,同时让更深的 Knowledge Retrieval 案例继续推进,但只带着一个更小、更具体的 delta。
iteration_2 = run_iteration(2, iteration_1)
{name: result["validation"]["passed"] for name, result in iteration_2.items()}
{'getting_started_evals_pre_repair.ipynb': True,
'qdrant_embeddings_search_pre_repair.ipynb': True,
'knowledge_retrieval_pre_repair.ipynb': False}
运行第 3 次迭代
第 3 次迭代聚焦于最深层的文档案例。
Knowledge Retrieval fixture 需要实现 API 形态现代化、保持可用本地数据运行,并保留检索教学流程。这些要求彼此之间可能会相互牵制:一次让 notebook 更现代的修复,可能会意外降低其可运行性;而一次让它保持本地化的修复,则可能移除过多原始教学内容。
第三轮会将最新的 notebook 和最后的验证 delta 一起交给 Codex。这部分演示展示了为什么迭代很重要:agent 会响应仍然存在的那个具体问题,而不是试图在一开始就预判一切。
iteration_3 = run_iteration(3, iteration_2)
{name: result["validation"]["passed"] for name, result in iteration_3.items()}
{'qdrant_embeddings_search_pre_repair.ipynb': True,
'getting_started_evals_pre_repair.ipynb': True,
'knowledge_retrieval_pre_repair.ipynb': True}
汇总改进情况
现在我们可以查看整个运行过程,而不必手动打开每个中间产物。下面的汇总展示了最重要的信号:哪些产物通过了、还剩多少验证发现,以及是否有 delta 被继续传递下去。
对于这里包含的 fixture,预期形态很简单:一个 notebook 在第 1 次迭代中通过,另一个在第 2 次迭代中通过,而最深的那个在第 3 次迭代中通过。在真实的维护工作流中,这个表会告诉你循环是在收敛,还是需要更清晰的约束或人工审查。
这个汇总对人工审查也很有用。维护者可以先从通过/失败模式入手,打开任何仍然带有 delta 的记录,并且只检查那些已经准备好审查的修复产物。
summary = []
for iteration, results in history.items():
for artifact, record in results.items():
validation = record["validation"]
summary.append(
{
"iteration": iteration,
"artifact": artifact,
"passed": validation["passed"],
"findings": len(validation["findings"]),
"remaining_delta": len(validation["remaining_delta"]),
}
)
summary
for row in summary:
print(
f"iteration={row['iteration']} artifact={row['artifact']} "
f"passed={row['passed']} findings={row['findings']} delta={row['remaining_delta']}"
)
iteration=1 artifact=qdrant_embeddings_search_pre_repair.ipynb passed=True findings=0 delta=0
iteration=1 artifact=getting_started_evals_pre_repair.ipynb passed=False findings=0 delta=1
iteration=1 artifact=knowledge_retrieval_pre_repair.ipynb passed=False findings=1 delta=3
iteration=2 artifact=getting_started_evals_pre_repair.ipynb passed=True findings=0 delta=0
iteration=2 artifact=qdrant_embeddings_search_pre_repair.ipynb passed=True findings=0 delta=0
iteration=2 artifact=knowledge_retrieval_pre_repair.ipynb passed=False findings=0 delta=1
iteration=3 artifact=qdrant_embeddings_search_pre_repair.ipynb passed=True findings=0 delta=0
iteration=3 artifact=getting_started_evals_pre_repair.ipynb passed=True findings=0 delta=0
iteration=3 artifact=knowledge_retrieval_pre_repair.ipynb passed=True findings=0 delta=0
这个汇总告诉了我们什么
重要的信号不是 Codex 做了编辑。重要的信号是,随着循环运行,剩余的验证 delta 在不断缩小。
| Pass | 要关注的信号 | 为什么重要 |
|---|---|---|
| Iteration 1 | 最简单的 fixture 通过;更深的 fixture 保留一个较小的 delta。 | 这个循环能够完成初始修复,同时把仍然需要证据的案例继续往后传递。 |
| Iteration 2 | 中等深度的 fixture 在看到验证反馈后通过。 | 运行时和 judge 反馈会变成有用的修复指令。 |
| Iteration 3 | 最深的 fixture 通过,或留下一个聚焦明确的最终 delta。 | 这个循环会收敛,或者为人工审查者生成清晰的交接内容。 |
record.json 文件让这一切变得可审计。一份有用的记录需要回答四个问题:审查发现了什么、Codex 改了什么、notebook 是否执行成功、以及还剩下什么?这正是“看起来很厉害的编辑”和“维护者可以信任的修复工作流”之间的区别。
泛化为连续循环
上面固定三次传递的运行方式有助于讲解这种模式。生产环境中的循环应当能够自行决定何时停止。
一个好的循环通常会因为以下四种原因之一而停止:验证通过、循环达到最大尝试次数、剩余差异不再变化,或者下一步决策需要人工审查。这些停止条件与修复提示同样重要。
另一个生产细节是审计轨迹。为每一次传递保留审查发现、修复后的工件、验证结果、验证判断以及剩余差异。这些记录能让维护者理解为什么循环会继续、为什么会停止,以及哪个工件已准备好接受审查。
def repair_until_done(max_iterations: int = 3) -> dict[int, dict[str, Any]]:
current_notebooks.update({path.name: path for path in NOTEBOOKS})
previous = None
loop_history = {}
for number in range(1, max_iterations + 1):
previous = run_iteration(number, previous)
loop_history[number] = previous
if all(record["validation"]["passed"] for record in previous.values()):
break
return loop_history
这还能应用在哪里
这个 notebook 演练只是讲解这种架构的一种方式。只要 agent 修改的是某个在被接受前需要经过不止主观审查的文件或流程,同样的模式都会有帮助。
一些高价值示例:
- 协议优化: 起草一份更新供专家审查,然后根据剂量规则、时间约束或必需的安全检查对其进行验证。
- 监管整改: 起草对受监管内容的更新,然后检查必需措辞、引用、审批以及特定司法辖区术语是否保持完整。
- 支持知识刷新: 更新一篇文章,根据当前产品行为或已知解决方案对其进行测试,并将不匹配项带入下一次传递。
- 代码现代化: 替换已弃用的 API,运行测试或静态检查,并利用剩余失败来指导下一次修复。
共同点在于,变更本身很重要,并且每一次传递都需要证据。无论目标是 notebook、策略、协议、支持文章、流水线还是代码库,这种循环都为 agent 提供了一种改进目标的方式,同时产出维护者可审查的证据。
结论
迭代修复循环使 agent 式维护更易于审查和运作,因为它将判断与证据分离开来。
审查负责发现候选问题。修复负责进行有针对性的编辑。验证负责执行工件并生成下一轮差异。当这些阶段交换结构化输出时,整个工作流会更容易检查、复用和调整。
核心思想很简单:不要依赖单次传递,而是为工作流提供一种从工件中学习、进行有界修复并根据真实验证反馈作出反应的方法。这个小小的改变,会让 agent 式维护变得更加切实可行。